

Authors:
(1) Shengqiong Wu, NExT++, School of Computing, National University of Singapore;
(2) Hao Fei ,from NExT++, School of Computing at the National University of Singapore, serves as the corresponding author: [email protected].
(3) Leigang Qu, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];;
(4) Wei Ji, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];;
(5) Tat-Seng Chua, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];.
Table of Links
- Abstract and 1. Introduction
- 2 Related Work
3 Overall Architecture
4 Lightweight Multimodal Alignment Learning - 5 Modality-switching Instruction Tuning
- 5.1 Instruction Tuning
- 5.2 Instruction Dataset
- 6 Experiments
- 6.1 Any-to-any Multimodal Generation and 6.2 Example Demonstrations
- 7 Conclusion and References
4 Lightweight Multimodal Alignment Learning
To bridge the gap between the feature space of different modalities, and ensure fluent semantics understanding of different inputs, it is essential to perform alignment learning for NExT-GPT. Since we design the loosely-coupled system with mainly three tiers, we only need to update the two projection layers at the encoding side and decoding side.
4.1 Encoding-side LLM-centric Multimodal Alignment
Following the common practice of existing MM-LLMs, we consider aligning different inputting multimodal features with the text feature space, the representations that are understandable to the core LLM. This is thus intuitively named the LLM-centric multimodal alignment learning. To accomplish the alignment, we prepare the ‘X-caption’ pair (‘X’ stands for image, audio, or video) data from existing corpus and benchmarks. We enforce LLM to produce the caption of each input modality against the gold caption. Figure 3(a) illustrates the learning process.
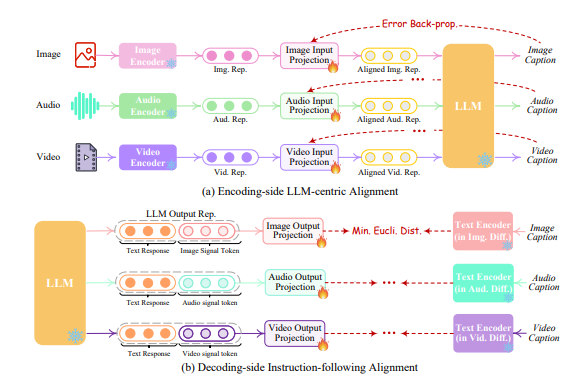
4.2 Decoding-side Instruction-following Alignment
On the decoding end, we have integrated pre-trained conditional diffusion models from external resources. Our main purpose is to align the diffusion models with LLM’s output instructions. However, performing a full-scale alignment process between each diffusion model and the LLM would entail a significant computational burden. Alternatively, we here explore a more efficient approach, decoding-side instruction-following alignment, as depicted in Figure 3(b). Specifically, since diffusion models of various modalities are conditioned solely on textual token inputs. This conditioning diverges significantly from the modal signal tokens from LLM in our system, which leads to a gap in the diffusion models’ accurate interpretation of the instructions from LLM. Thus, we consider minimizing the distance between the LLM’s modal signal token representations (after each Transformer-based project layer) and the conditional text representations of the diffusion models. Since only the textual condition encoders are used (with the diffusion backbone frozen), the learning is merely based on the purely captioning texts, i.e., without any visual or audio resources. This also ensures highly lightweight training.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.